
Why we chose to build our own data platform in an archaic landscape
Written by
February 10, 2022
|
Approximately a 00 minutes read
Product
Build or buy? Intility ventured into the Norwegian mobile operator landscape a couple of years back. Immediately we faced a difficult decision regarding what would become the data platform for Intilitys mobile operator service. Here we will outline the problem, the alternatives and how we built it.
Before you can launch your own mobile operator platform you will be faced with several, important and difficult decisions. One of these are: how are you going to handle billing?
In the world of telcos billing is the ability to receive Call Detail Records (CDR) files, store, process and transform them into actionable data for the end user, i.e., invoicing and usage. But it can also give us important and valuable information for insights and troubleshooting, so our end goal was a data platform for our mobile operator service. To be specific, a CDR file contains data related to the mobile subscribers, among other things, ongoing usage and cost for different mobile services such as voice, SMS and data.
The challenge
We strive to work in an agile and modern way, but that doesn’t always match so well with traditional telco. For instance, when it came to billing our expectations were to get a readymade billing API that we could integrate with our platform that would fit nicely with our data driven development. The reality was that the mobile operator we rent network access from delivered its billing data in encoded binary files (CDRs) via a file sharing service on an hourly basis. Not exactly what we had in mind. So how could we solve this?
Sample binary CDR file:
a€d _DNORNC_6NCPHN_m20373lP20190213155817_g+0100cP20190213155817_
g+0100kP20190213155817_g+0100_I_=
"#_# SVVOTGAS06002: 2027 Bussbillette(_NOK_RSDRPj_i_ _hpæ_tfùji_h_g+0100<Þ7_
8_:_ƒCONS-NO7_8_:_ƒ
212.45.177.427_8_:_ƒ
0.0.71.1467_8_:_ƒMMSNC027_8_:_ƒSMS17_8_:_ƒMSS027_
8_:_ƒBW017_8_:_ƒROAM1237_8 _:_ƒCPAc€iËOƒ+G_$
&` _G’ `Y_ƒG€_‚471880,P20190131005135_h__ ‚...The options
There are different options to tackle the billing issue. There exist solutions ranging from complete billing-as-a-service, lots of different software bundles and separate software components you can choose from and, of course, we could decide to develop everything ourselves 😱. It appears we inadvertently stumbled upon our own “build or buy”-dilemma.
Billing-as-a-service comes as more or less turn-key solutions, with low configuration efforts but offer limited customization options. Since we already have parts of a billing platform in place for our existing IT-services, i.e., invoicing our customers, we decided that it was not a good fit for us as it would be more than we need (or too much to change the whole operation) and give us too little flexibility when it comes to customization and integration.
Operator specific SW bundle would mean a lot of the same things mentioned above. Even though it would provide better customization and integration possibilities, it would come at a higher cost and be more of a lock-in solution.
Separate components would mean more flexibility regarding customization and integration, but a lot more effort needed from our side in the whole process, from research, to installation, to customization and integration to get all the different parts to fit together.
Develop everything ourselves from scratch would mean full flexibility with respect to customization and integration but also a lot of development effort! Too much effort, and it would also require too much domain specific knowledge into CDRs (call detail records), TAP3 specification, ASN.1 standard, and itty gritty inner workings and details.
The solution
After using a lot of time researching the different options it became clear to us that neither sort of fit the bill, at least not good enough for our expectations. So, we decided to build our own solution. We found that we could buy small SW components that could solve some domain specific issues, create our own generic data and service APIs, integrate with our existing billing components and stitch everything together in a neat way.
The CDR files are sent via SFTP every hour and stored to local storage. Over time this will grow into a huge amount of files! We needed to store the files in a secure, durable and flexible way and decided that object storage would fit well. Our first challenge was to find a way to get every file we receive into the object storage solution. We created a small event driven API that triggered on new files and copied them into a blob container.
Next, we needed to decode the files and transform them into readable files. Here we found a small software component we bought, a CDR converter, that could handle the decoding for us. That way we didn’t have to deep-dive into the intricate standard for ASN.1 encoding. The software was in fact a java based CLI tool. We needed to automate the conversion process, so we wrapped it in another small API that we could trigger with events from new files in the blob container. It then decoded every new file and stored the decoded xml files in another blob container. We decided to containerize the solution with Docker and run it in Azure container instance. ACI is a serverless container platform, meaning it’s easy to deploy and scale and you only pay for what you use.
Sample decoded CDR file:
<?xml version="1.0" encoding="UTF-8"?>
<Decoded_convertedcdr>
<DataInterChange>
<transferBatch>
<batchControlInfo>
<sender>NORNC</sender>
<recipient>NCPHN</recipient>
<fileSequenceNumber>20373</fileSequenceNumber>
<fileCreationTimeStamp>
<localTimeStamp>20190213155817</localTimeStamp>
<utcTimeOffset>+0100</utcTimeOffset>We now had readable CDR files. As noted in the intro, a CDR file contains data related to the mobile subscribers ongoing usage and cost for different mobile services. This data needs to be structured, controlled and stored in a database. Here we got help from our data science team to write the logic needed to achieve this. They, as many other data scientists, prefer to write code in Python, especially when it comes to handling huge sets of data. This became our third little API, triggered by events when new decoded files are added to the blob container.
We decided to use a document db solution to store the processed data. We landed on Azure Cosmos db, which is a high available, elastically scalable NoSQL database. It gave us easy scaling as we continued to expand the dataset, as well as the growing load of the consuming APIs with their increasing number of queries.
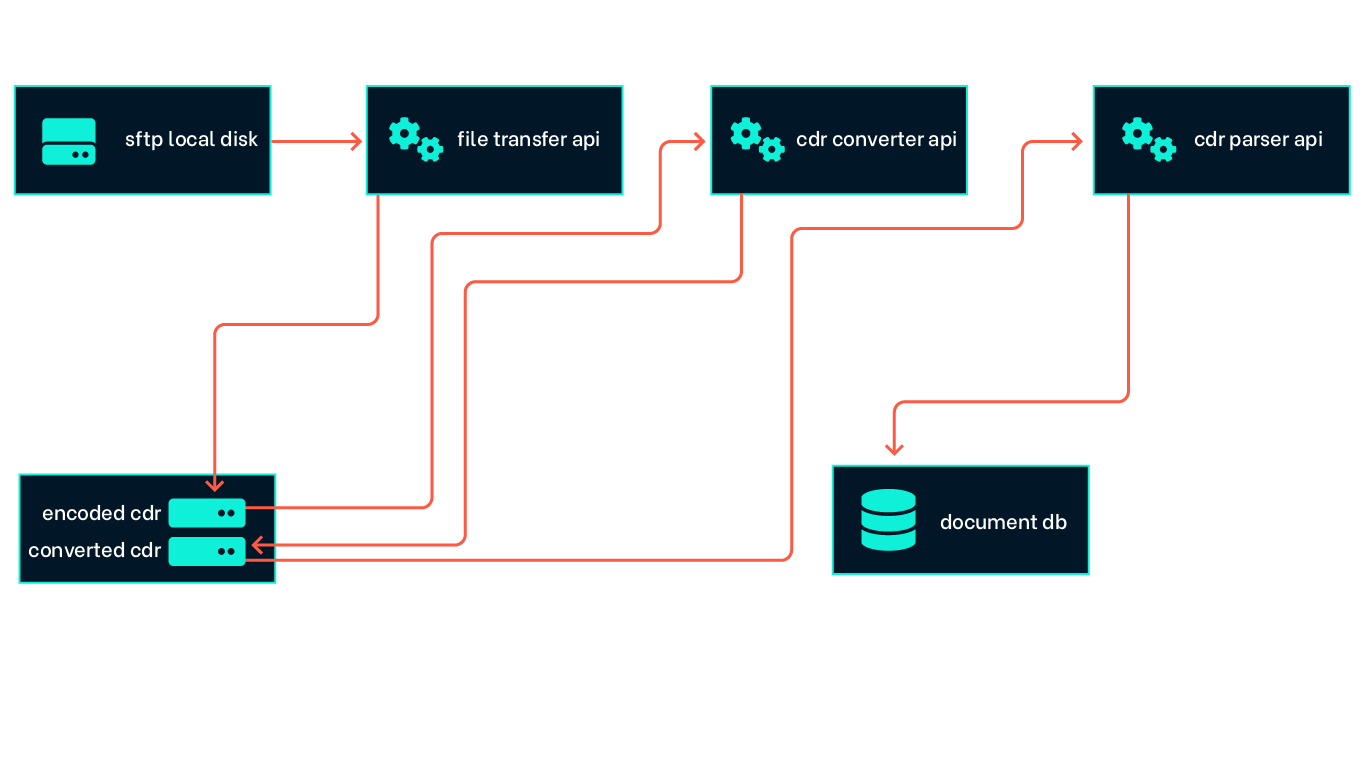
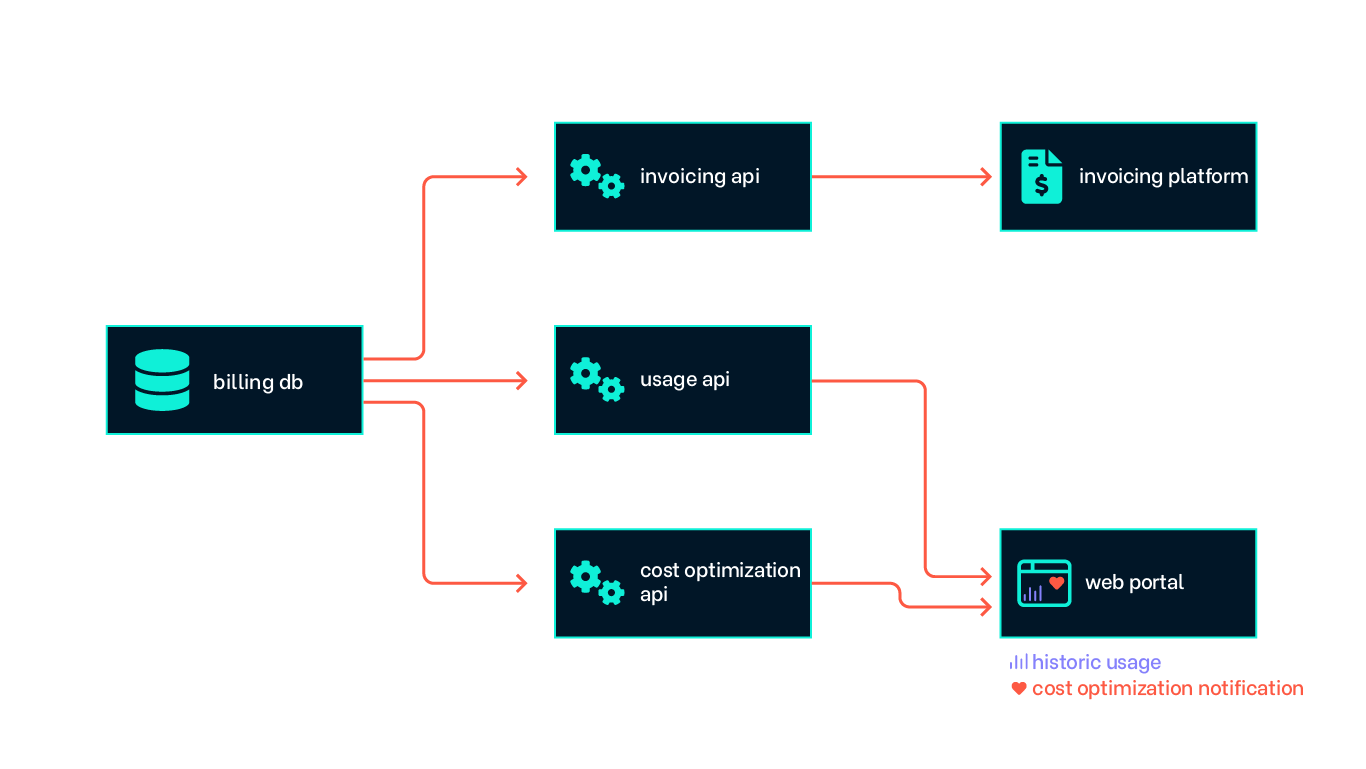
At this point we reached the foundation for a billing data platform. From here on we could start to focus on what we wanted to do with and get out of the billing data. The most obvious starting point was to make sure we could charge our end users for their mobile usage and give them insights into their own usage over time. We created an invoicing API that integrated with Intility's invoicing platform which already handles the processing and shipping of invoices to our customers. We then created a usage API that aggregated usage data over time to provide both historic usage data and inter-period/month usage to the end user.
We also created automated historic usage analytics that mapped actual usage to the subscription package, that we then provided back to the end user in actionable recommendations to optimize cost for their subscriptions. This became the cost optimization API.
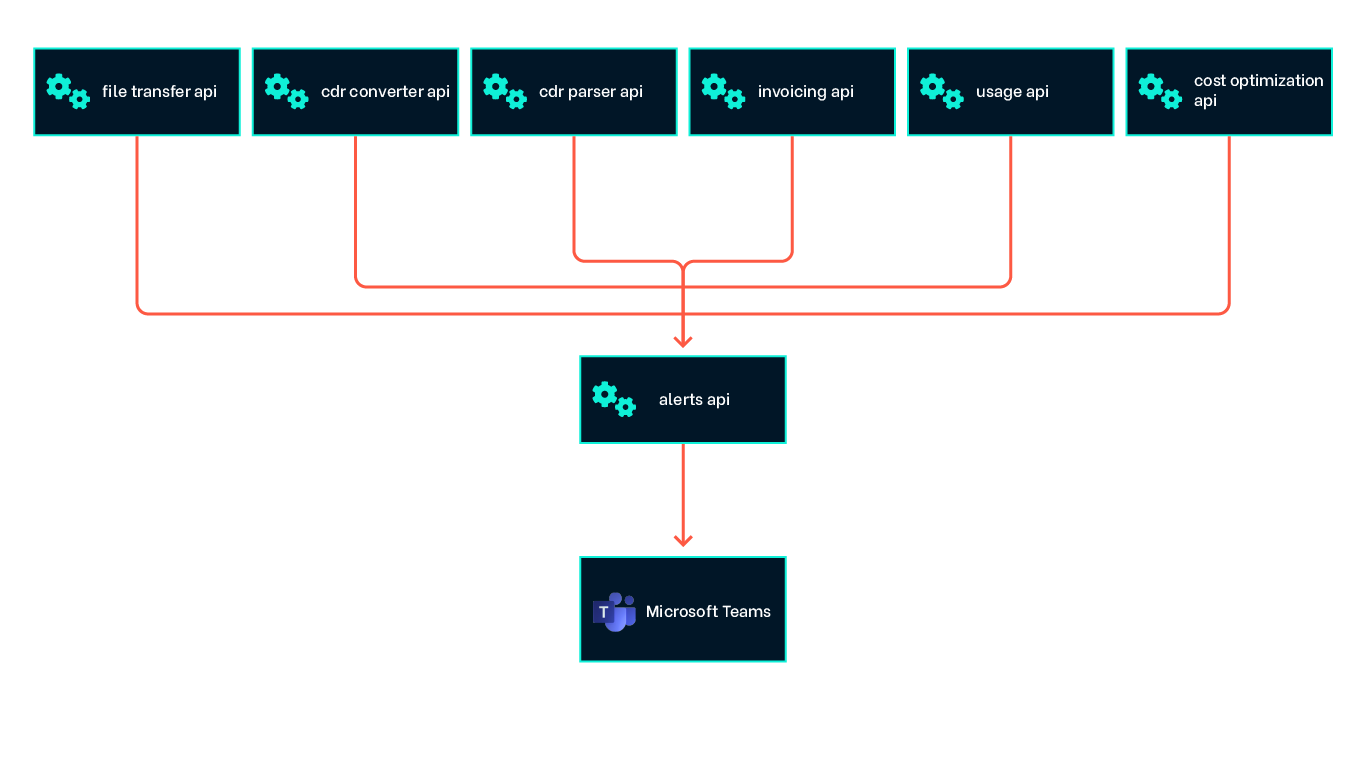
Controlling that the billing data is complete and correct, that we have accounted for every call detail record in all the CDR files, is of utmost importance. We added error handling, control logic and alerts that notified us of any issues detected during the path from the starting point of unreadable CDR files handed to us via SFTP, all the way to readable structured data in our database.
At Intility Microsoft's solutions are heavily utilized in the workplace, and hence Teams is our main means of communication. We therefore decided to integrate the alerts into the communication tool that everyone already is familiar with and use. We created a separate alerts API that aggregated alerts from all our different services and solutions and integrated it with Teams. We could then add new alerts and notifications with ease as we continued to expand our solution. It would also be easy to change or add new relevant channels to reach the desired colleagues as effectively as possible.
Closing words
I would like to end this article with some lessons learned and thoughts on future improvements.
It is important to give yourself enough time for research and planning to make the best decisions. If you hit a roadblock, see if you can temporarily skip to another part or start with an easier way to solve the task at hand. You can always improve it later when you have matured on the subject. I think we found a pretty good balance during this project.
Even though we weren't ready for a full event driven microservices architecture, we tried to keep those principles in mind. We created relatively small, containerized APIs packaged in docker images and ran them in different hosting services based on needs/use-case.
Utilizing noSQL/document db can give you great flexibility, you can change and improve the data models along the way. That flexibility gave us a big advantage as we continued to develop the solution. But that flexibility also has its limitations. You must be a lot stricter in the application layer, or else your data will become harder to work with or in the worst case end up useless.
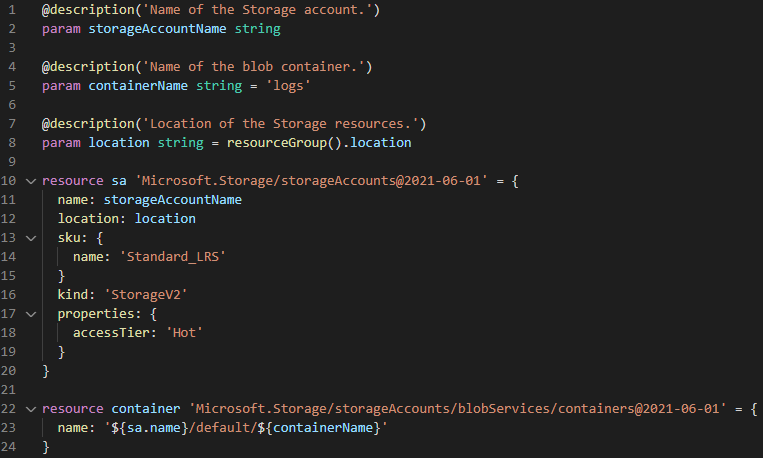
After testing different solutions and configurations manually we utilized infrastructure-as-code for every piece of infrastructure in this platform. Not only did this give us complete control over the different environments (dev, qa, prod) but it also meant we could save a lot of time on manual configuration and avoid problems due to configuration drift between environments. We continually wrote templates for the different infrastructure components we needed to standardize and implement best practices, which in turn meant we would save a lot of time deploying new instances of these infrastructure components both in this and other projects. Microsofts own IaC solution supports a JSON like syntax called ARM templates, which is very verbose, or their domain specific language called bicep. Here is an example of a bicep script to deploy a storage account with a blob container.
When building a distributed system like this, with so many moving parts, it will quickly become difficult to troubleshoot what is actually going on. We should have put more effort into addressing distributed tracing and logging from the get-go. That could have saved us time and eased our troubleshooting efforts significantly.
Some technological improvements we already have in mind and are currently planning for are for instance API management and microservices architecture.
API management can help us with improved control over all the different small APIs. We can standardize and offload some common implementation tasks from all the APIs. Some good examples are authorization and logging. That way the developers can focus on the core issue at hand, and not use a lot of time on these common implementation tasks.
Im not going to delve into all the pros and cons of microservices architecture, there are much better resources already available out there. But for this project we think that it could help us with better scaling, better fault isolation and resiliency. It would also mean smaller codebase per project, making it simpler to maintain, easier for new developers to get up to speed and for everyone to add new features faster.
Our services are already containerized, but we have not deployed them in an orchestrated container platform. Using a kubernetes framework to orchestrate all the parts of the distributed system would further enhance the solution with autoscaling, autohealing, and configuration management.
We have not reached the end of this journey. And we probably never will do either, as technology continues to evolve, and we will continue to add features to the platform. It is exciting times we live in; I feel privileged to be part of the team that are building out Intility's mobile operator platform and can't wait to see what it looks like in a couple of years!
if (wantUpdates == true) {followIntilityOnLinkedIn();}
Other Articles




Platform
June 26, 2026
Beyond Intelligence: Benchmarking Speed and Cost of Self-Hosted vs. Frontier LLMs

Erfan Mohammadi

