
Data Platform in Azure – A pathfinder
Written by
May 13, 2025
|
Approximately a 00 minutes read
Platform
Data platforms have evolved from being "something IT takes care of" to becoming the driving force behind digital transformation. The most successful companies use data not only for reporting, but to shape products, automate decisions, and create entirely new business models. But this requires a platform that is built for both the present and the future. So how do you make the right choice in an increasingly complex landscape?
Start with the needs – not the tool
Before diving into technology and products, take a step back and clarify what the platform is actually supposed to solve. It’s not just about collecting and storing data — it’s about addressing real business needs.
Is the focus on classic BI and fixed reports? Or do you need capabilities for exploration, collaboration, real-time data streams, and machine learning? Will there be many developers building pipelines and training models, or is the priority to enable business users with fast access to data through dashboards?
The answers to these questions shape both the architecture and the selection of services — and ultimately how the platform is built.
In this article, we’ll focus on services within Azure. This isn’t because other platforms lack value, but rather because many organizations — including ours — have already made significant investments in Azure. Identity, networking, monitoring, and security controls are often already in place, making Azure a natural foundation to build on. By leveraging existing infrastructure, we can reduce complexity, accelerate time to value, and stay aligned with operational best practices.
Build on what we already have
We’re not starting from scratch. You need to look at the platform choice in the context of the existing system landscape. Are you using Azure? Is identity, networking, and security already set up there? What kind of in-house expertise do we have?
The bottom line is simple: You need to build something you can actually operate and continue to develop over time.
Security and governance must be built in from the start
Don't wait until everything is up and running before thinking about security and data governance. Access control, logging, data quality, and lineage need to be in place from day one.
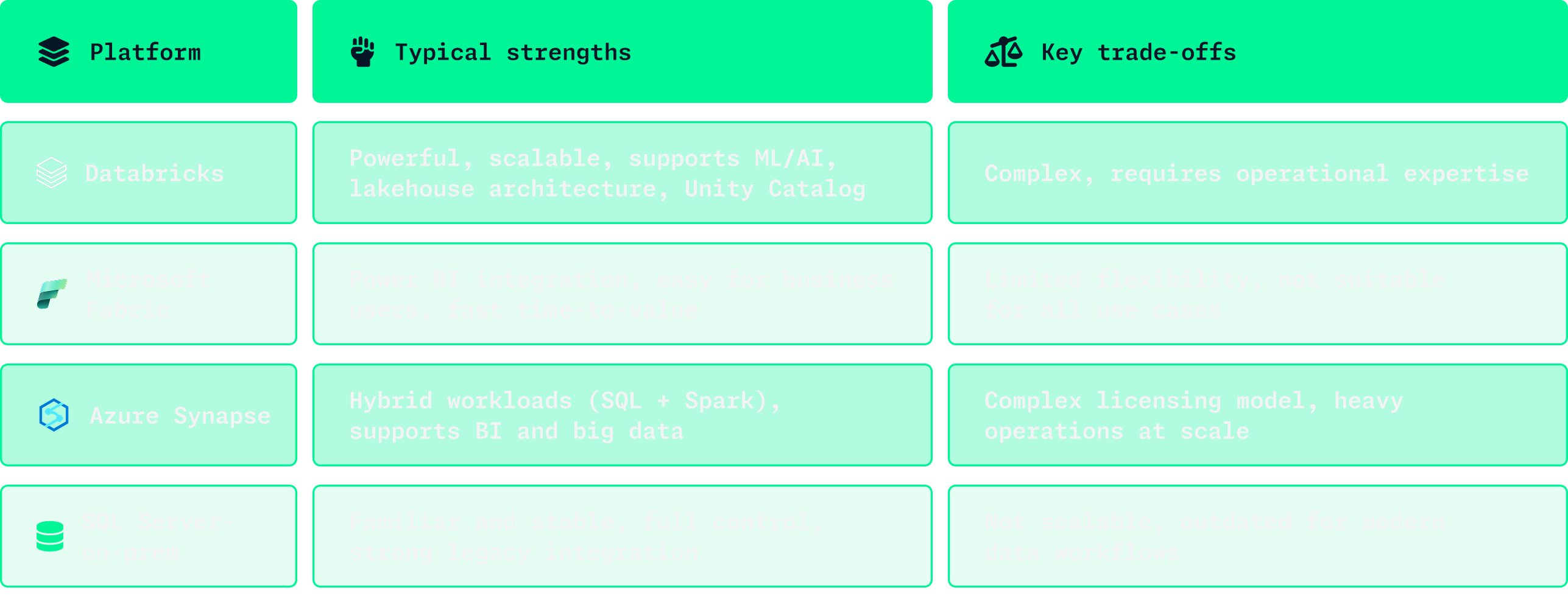
Databricks offers Unity Catalog, which provides solid support for dataset management and domain- or team-based access models.Fabric is easier to get started with but lacks some of the deeper governance features.SQL Server gives you full control – but that also means you’re responsible for managing all security and data quality yourself.
You need to assess: How much control do you need – and how much responsibility are you willing to take on?
Enterprise scale and accessibility – who should use what, and from where?
When building for enterprise use, you also need to consider how the platform is accessed:
- Should it be exposed to the internet, or only accessible via Private Link and internal networks?
- Who should have access – developers, analysts, partners?
- How will you handle tenant boundaries, policies, and network segmentation?
If you're building in Azure and already operating within an Enterprise Scale setup, your platform must align with landing zones, network policies, identity control, and tagging standards.
Databricks supports private endpoints and regional isolation well – but you need to configure it yourself. Fabric is easier to deploy, but gives you less fine-grained control.
This isn’t just about security – it’s about making sure the platform is accessible to the right people, in the right way, from the right places.
This is not a project – it’s a product
A data platform is never truly “done.” It needs to be operated, maintained, and improved continuously. That’s why you need to think about lifecycle and operations from the very beginning.
Make sure you have:
- Separate environments for dev, test, and prod
- CI/CD for pipelines and configuration
- Monitoring for performance and cost

Databricks gives you full flexibility, but you’ll need to set up most of it yourself.Fabric hides a lot of complexity and is great for fast delivery – but offers less flexibility.Synapse offers a bit of both – but comes with more moving parts to manage.
Choose an approach you can realistically support over time – both technically and operationally.
Cost needs to be manageable – not just traceable
Cost isn’t just about licenses – it’s about how resources are actually used. You need to track compute usage, pipeline cost, and data processing – and act before things get out of hand.
Databricks is consumption-based – flexible, but risky if you lack monitoring and budget controls.Fabric uses fixed capacity – more predictable, but less elastic.SQL Server gives you full visibility – but also full responsibility.
Set up alerts, budgets, and logging early. It’ll save you from unexpected surprises – and unnecessary technical debt.
When should you choose what?
Here are some simple guidelines:
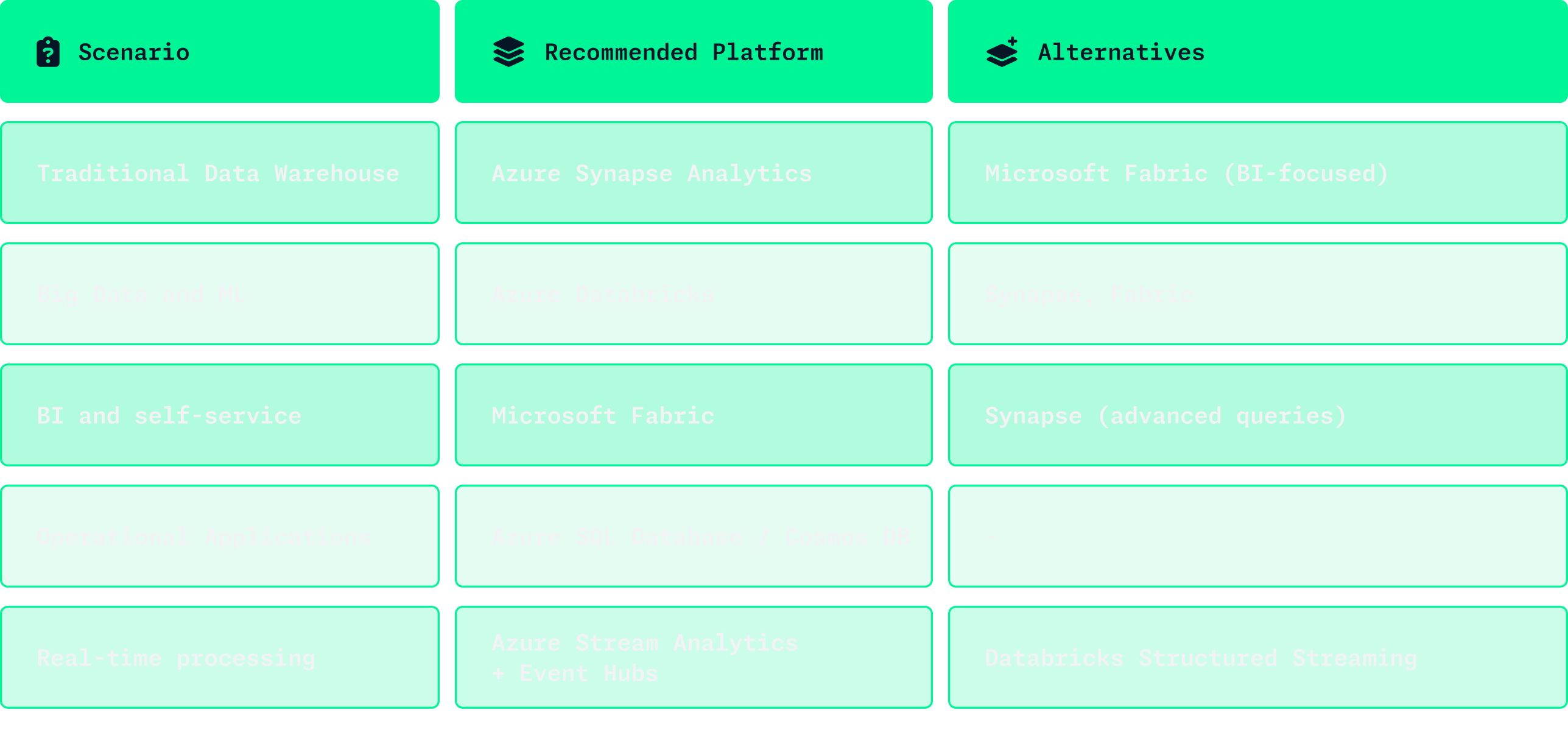
- Databricks: Ideal when you need flexibility, handle large volumes of data, or work with advanced analytics and machine learning—and have the technical capacity to manage it.
- Fabric: Best suited when the business side needs to build solutions themselves and you want a user-friendly, self-service environment.
- Synapse: A good middle ground if you need more performance and scalability than Fabric offers, but still want to stay within the Azure ecosystem and combine familiar SQL with Spark-based capabilities.
- SQL Server: The right choice when an on-premise, tightly controlled setup is required—and your team has the experience and processes to run it efficiently.
In reality, the most effective solution often lies in combining platforms. For example, Databricks can power data processing and model training, while Fabric handles reporting and business-friendly insights. Choose the right tool—or combination—for the right part of the job.
Conclusion
So if i should conclud i will say building a data platform isn’t about choosing the most advanced tool – it’s about solving the right problems in a sustainable way. You have to start with the needs: Who will use the platform, what do they need to achieve, and what are the requirements for security, operations, and accessibility? The answers to these questions should drive your technology choices, architecture, and operating model.
There is no one-size-fits-all solution. Databricks gives you power and flexibility – but requires technical expertise and ownership. Fabric enables fast results for the business side – but offers less control. Synapse and SQL Server offer a middle ground, but require a solid understanding of each platform’s strengths and limitations.
That’s why you shouldn’t think in terms of “either/or” – but rather “both/and.” In many cases, the most effective solution is a combination, where different tools serve different needs. At the same time, you should build on what you’ve already invested in – both technically and organizationally – and make sure the platform can evolve, be operated, and be governed in a way that fits your reality.
Ultimately, this is not a project – it’s a product. A product that must create value over time – through strong governance, continuous improvement, and focused use.
Here are some example use cases
📊 Use Case: Provide leadership with timely insights
Combination: Databricks + Power BI (via Fabric)

The data team uses Databricks to ingest and transform data from multiple sources (ERP, CRM, real-time streams). The output is stored as Delta Lake tables or views. These are exposed to Power BI via Direct Lake (Fabric), enabling the business side to build reports independently.
Power BI queries the data directly without duplicating it, resulting in low-latency insights.
How it works:
- Ingest & Transform in DatabricksThe data team uses Databricks to gather and process data from multiple sources — such as ERP systems, CRM platforms, and real-time streams. Transformations are applied using Spark or Delta Live Tables, and the output is stored in Delta Lake.
- Expose via Direct Lake (Fabric)The transformed Delta tables or views are made accessible to Power BI using Direct Lake, a feature in Fabric that enables querying data directly from the lake without importing or duplicating it.
- Self-Service Reporting in Power BIBusiness users can connect directly to these datasets and build interactive reports and dashboards. Since there's no data copy involved, they benefit from low-latency access to the freshest data — without relying on daily refresh schedules.
Strength & Value:
- Strength: Complex data preparation + self-service analytics
- Value: The data team can focus on engineering, while the business creates its own reports
📈 Use Case: Visualize real-time data with low complexity
Combination: Fabric + Azure Event Hub
Sensors or external systems push messages into Azure Event Hub. Fabric's ingestion services pick up the data streams and make them available in Power BI in near real time.
This enables live dashboards for monitoring logistics, production, or user activity – without writing much code.
How it works:
- Stream Data via Azure Event HubExternal systems, such as IoT devices, applications, or telemetry services, push real-time messages into Azure Event Hub. This acts as a scalable data ingestion backbone for streaming scenarios.
- Ingest Seamlessly with FabricFabric's real-time ingestion services automatically pick up these data streams from Event Hub. There's no need to build complex pipelines — the integration is designed to be low-code and efficient.
- Visualize in Power BIAs the data flows in, it becomes available in Power BI almost instantly. This allows users to create and monitor live dashboards for operations like logistics tracking, production line monitoring, or user activity analysis.
Strength & Value:
- Strength: Rapid real-time visualization with minimal dev effort
- Value: Quick path from event stream to business insight
🔄 Use Case: Transform big data efficiently and expose it to SQL tools
Combination: Databricks + Azure Synapse Analytics
Databricks handles ingestion and transformation of large, complex datasets – such as log data, IoT streams, or large third-party CSVs. This is done using Spark or Delta Live Tables, optimized for heavy ETL and advanced business logic.
Transformed data is written to shared storage (e.g., ADLS Gen2), and then made accessible through Synapse Serverless SQL. This enables analysts to use familiar SQL tools, Power BI, or even existing data warehouse queries.
How it works:
- Ingest & Transform with DatabricksDatabricks takes care of ingesting and processing large-scale, complex datasets — including logs, IoT data, or external CSV files. This is typically done using Apache Spark or Delta Live Tables, which are well-suited for high-throughput ETL pipelines and advanced transformation logic.
- Store in Shared Data LakeOnce transformed, the data is written to a shared data layer, such as Azure Data Lake Storage Gen2 (ADLS Gen2). This creates a single source of truth that can be accessed by both platforms.
- Query with Synapse Serverless SQLAzure Synapse Serverless SQL reads the transformed data directly from the lake. This makes the data instantly available to analysts and BI tools using familiar SQL-based workflows, without needing to move or duplicate the data.
Strength & Value:
- Strength: Combine modern data processing (Databricks) with traditional SQL-based analytics (Synapse)
- Value: Best of both worlds – scalable transformation + easy access for analysts
🧠 Use Case: Generate contextual answers from enterprise data
Combination: Databricks + Azure OpenAI
Scenario:Your organization has large volumes of internal reports, logs, documentation, and support tickets stored in structured and unstructured formats.You want users to be able to ask natural language questions and get meaningful, context-aware answers – without manually digging through files or dashboards.
How it works:
- Databricks is used to process and structure the data: it ingests documents (PDF, HTML, JSON, etc.), extracts metadata, chunks and embeds the content using models like text-embedding-ada-002.
- The resulting vector index is stored in a managed vector store (e.g., Azure Cognitive Search or a custom vector DB).
- When a user asks a question, the query is sent to Azure OpenAI (e.g., GPT-4) along with relevant chunks retrieved from the vector index (RAG – Retrieval-Augmented Generation).
- The model responds with a tailored, data-aware answer.
Strength & Value:
- Strength: Combines scalable data processing with cutting-edge natural language capabilities
- Value: Unlocks access to organizational knowledge through conversational interfaces – without needing to build a full search engine
if (wantUpdates == true) {followIntilityOnLinkedIn();}
Other Articles




Platform
June 26, 2026
Beyond Intelligence: Benchmarking Speed and Cost of Self-Hosted vs. Frontier LLMs

Erfan Mohammadi

