
Realizing the potential of Machine Learning with ML Ops
Written by
December 4, 2023
|
Approximately a 00 minutes read
Data
This article describes Intility's strategic adoption of ML Ops and how it enables ML solutions, optimizes operational efficiency, and automates tasks that were once exclusively done by humans.
Demystifying ML Ops
What it is
Let’s start with the definition: in simple terms, ML Ops, or Machine Learning Operations, is generally about effectively managing and putting ML (machine learning) models to work in the real world.
ML Ops is a collective term which includes tasks such as deploying models so that they can be used by people or integrated into other applications. It also covers the task of keeping an eye on how well the models are performing, making sure they're accurate and reliable. In addition, ML Ops makes it easier to track changes, reproduce experiments and ensure everyone is using the latest version of models.
What it isn’t
Well, there's quite a bit that falls outside its scope. However, areas closely related, like training ML models and setting up a service for serving ML models are distinct topics that will not be addressed here. In contrast to those topics, engaging with ML Ops doesn't necessarily demand mathematical or coding expertise, and the same applies to the content of this article.
Auto Dispatch - an example of ML @Intility
At Intility, we are training lots of ML models, forming the backbone of our ML Ops approach (because there's no ML Ops without some ML!). To make things relatable as we go through this, let's take a quick look at one of our models called Auto Dispatch.
Intility receives hundreds of inquiries each day about network connectivity, license management, printers or anything related to IT. We have different specialized departments handling these different types of inquiries and historically it has been a manual process deciding what department should solve which inquiry. By using the text in the inquiries, the ML model Auto Dispatch was trained to find the best possible match of specialized department.
Today Auto Dispatch automatically dispatches inquiries about licenses to the license department and inquiries about printers to the print department. If an inquiry is about the license of a printer, it is likely to be unsure and hand over the decision to a human.
The approach of ML @Intility
To really make the most of Machine Learning, it's not just about training a high-performing model. It is vital to understand that a model's effectiveness is closely linked to the quality and relevance of the data it relies on. Maintaining high performance in the future requires proactive action today, acknowledging the dynamic nature of data and that data is changing over time.
We have developed an application called ML Portal which serves as an essential tool for ML Ops at Intility. ML Portal facilitates data management for all our models and providing a platform for efficient data labeling and data generation. ML Portal is also used for monitoring models in production and acting as a seamless bridge to integrate models into various applications.
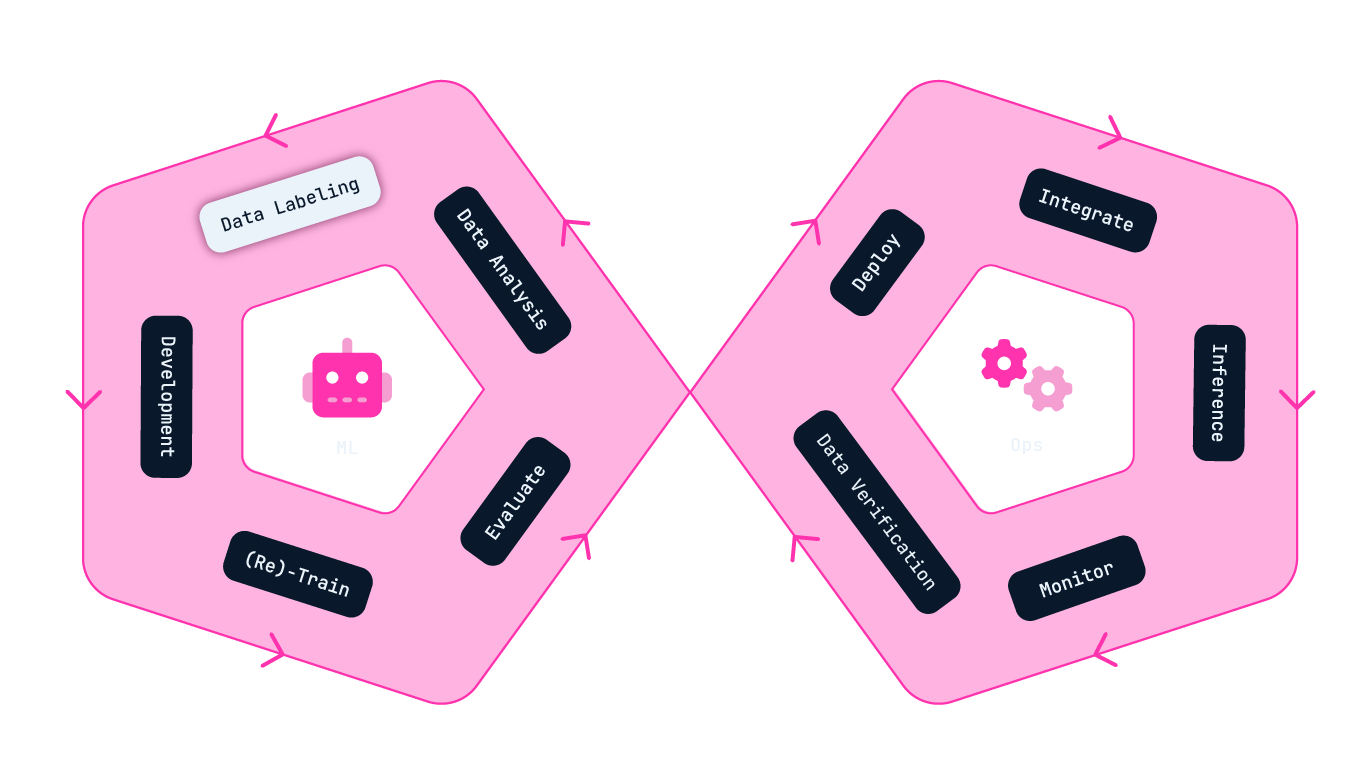
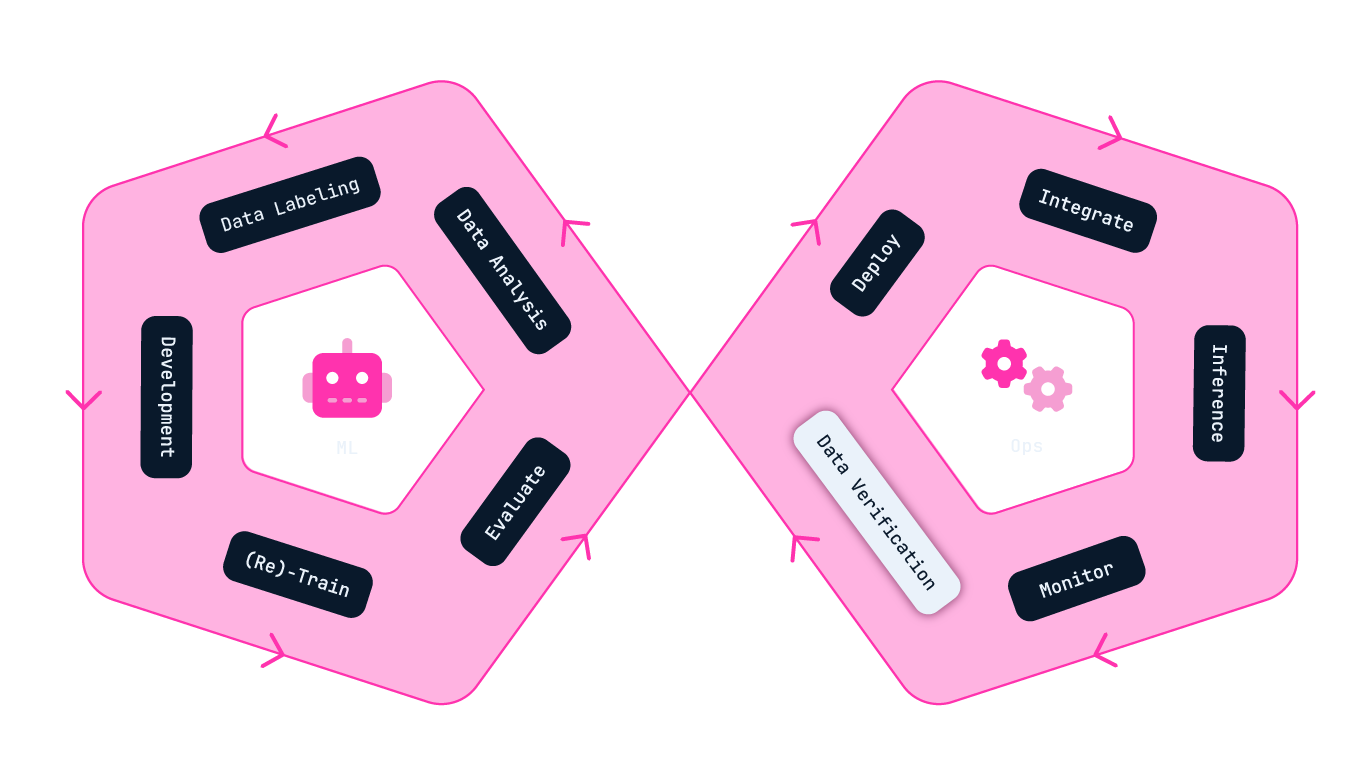
The infinity cycle of ML Ops
To ensure we have an up-to-date model every single day, it's crucial to train the model using the most recent data. This means the model needs to be retrained several times throughout the year, underscoring the significance of a seamless training process. Viewing model training and ML Ops as a one-time task is not valid. Instead, it should be seen as a repeating cycle.
Whenever ML Portal is updated with new labeled data, our own developed script starts a process to retrain a new model. After that, the model's performance is evaluated before it's deployed and served via an API. The API enables us to integrate the model into different applications, where the model collaborates with people in their everyday tasks - a process known as inference. ML Portal efficiently monitors model actions, and humans can verify whether they are correct or incorrect, either in a batch or seamlessly as part of their work routine. All of this data is analyzed and automatically labeled within ML Portal. This leads to new labeled data that will be used when training the next model.
And there we have it - we have successfully tied together the infinity cycle of ML Ops.

Step-by-step in the Infinity cycle of ML Ops
The infinity cycle is split into two parts - the left circle involves ML phases, and the right one involves Ops phases.
The left circle focuses on what most people associate with machine learning, such as training and fine-tuning a model based on a given dataset. This is something you might find familiar from university studies.
The right circle is the operational part, where the model is integrated into everyday tasks and generates value for the business. Enhancing business value isn't a straightforward journey as it includes real-world factors like user experience and how well humans and machines collaborate.
Machine Learning phases
Data Analysis

The initial phase of the infinity cycle involves theoretical data analysis. This means figuring out what problems you aim to solve with the ML model. The majority of our ML models, including Auto Dispatch, are classification models. These models are trained using labeled data that's sorted into various categories.
Referring to Auto Dispatch, inquiries about licenses have a license label and inquiries about printers have a print label. If we have a decent quantity of examples for each topic, the model should theoretically be capable to classify the inquiries accurately. The exact quantity of examples depends on the quality of the data, namely, the presence of noise in the data and the occurrence of mislabeled inquiries. However, if we don’t have any labeled inquiries about topics like printer licenses, the model would only guess randomly for these inquiries, which isn't what we're aiming for.
To sum up the Data Analysis phase, we’re doing a theoretical analysis about whether we have all the necessary data we need for the model to address the problems we want to solve.
Data Labeling
Moving on to a more hands-on part of data work, this step involves using the insights gained from the earlier Data Analysis phase to improve and label the data properly. Some scenarios in which data labeling is needed include when there is:
- Not enough labeled data - like the example with printer licenses.
- Incorrectly labled data - In any system or organization that relies on data accuracy, any inaccuracies or mistakes in data labelling can lead to inefficiencies or errors.
- Outliers in the dataset - we don't want to train our model on non-representative data.
All the data labeling happens within ML Portal. Using Auto Dispatch as example, this lets an employee in the print department manage the inquiries with a print label, and the same applies to employees across all our departments. In this manner, we have established a platform that encourages every department to take ownership of their own data, ensuring significantly higher data quality than labeling by non-specialists could achieve.
If it was found during the Data Analysis that there were not enough examples of printer licenses among the labeled inquiries, then there are two ways to fix this in ML Portal, either by labelling real world examples or generated examples.
Labeling real world examples
Over the past few years, our primary way of labeling data has been using real-world examples. In the case of Auto Dispatch, these real-world examples are inquiries written by our customers. This method has worked well for numerous models, as it reflects the type of data the model encounters during its operational phase.
However, it is a time-consuming manual process to label real world examples which also has led to a slightly skewed dataset. The main reason for this skew is that most of Intilitys’ inquiries are in Norwegian Bokmål, leading to poorer performance of the model on inquiries in less frequent languages like Norwegian Nynorsk, English or Swedish.
Labeling automatically generated examples
The second and newly invented method for labeling in ML Portal is through the use of large language models (LLMs) and generative AI. By utilizing Azure OpenAI, we have deployed multiple GPT models that are integrated with ML Portal. This integration enables us to label generated synthetic data, ensuring an even distribution across all the languages our customers use. Additionally, this method allows for labeling to be done in a very time-efficient manner.
For incorrectly labeled data, there are different possible approaches. One method is to go through all the mislabelled data points and relabel them. However, when there are hundreds of mislabeled data points, it’s often easier to delete the labels and repeat the steps used when there is not enough labeled data, either by labeling real-world data or automatically generating data.
Outlier data might confuse the ML model and is preferably removed from the dataset. This can be handled in ML Portal by selecting a data point and discarding it accordingly.
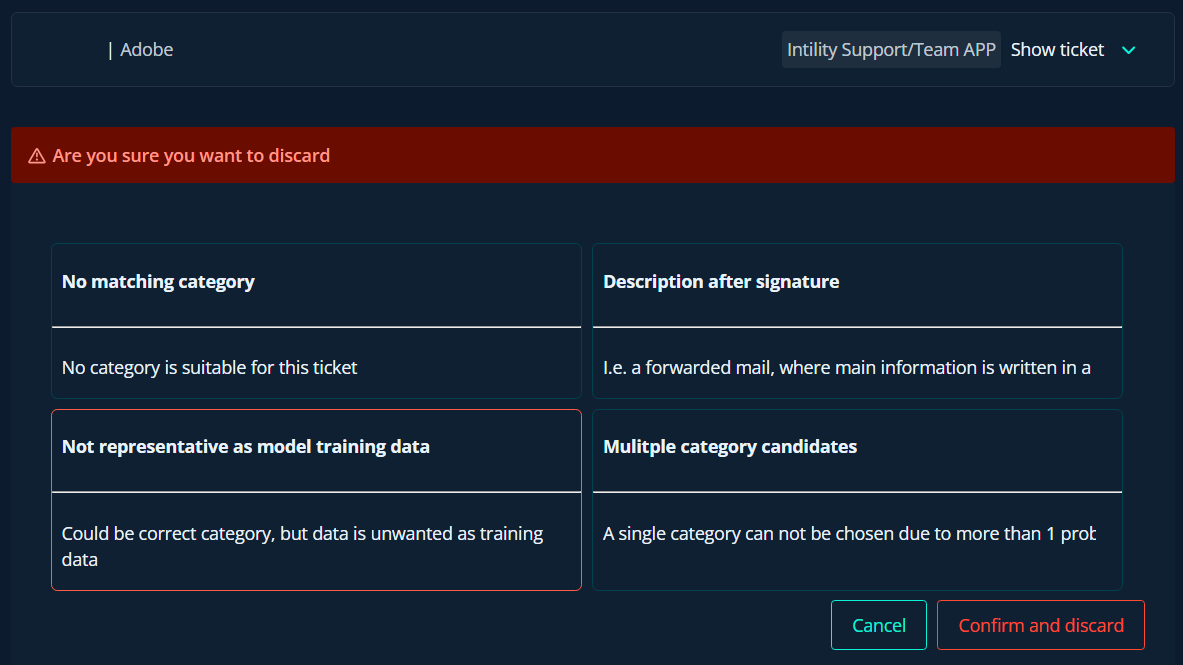
There could be various resons why a data point isn't suitable as training data and should be discarded.
Development

The development phase is where the core of machine learning takes place. Data from ML Portal is extracted, followed by the classical steps of machine learning such as data preparation, feature extraction, cross validation and algorithm & parameter optimization.
Our development strategy at Intility has been to initially find a model that works well and then enhance it by providing more data with higher quality. It's simpler to see performance improvements when you consider data quality, making it easier to justify investing time into refining the model. However, it's crucial for the development phase to seamlessly fit into the ML Ops cycle, allowing for changes to be made whenever necessary.
(Re-)Train
Using the resulting code from the development phase, we trigger the process that starts the training process, where the model is trained using the latest data from ML-Portal. In every loop in the ML Ops cycle except the first, this phase is referred to as Retrain, as it involves updating and refining the model based on new data and insights gained from the previous ML Ops cycle. Depending on the amount of data and the type of algorithm used in the development script, this can be a time-consuming and computationally intensive process.
Evaluate
We now have a fresh new model crafted during the (Re-)Train phase, but before we unleash it into the real world, we must test the model to make sure it works as expected. The way we test a ML model is by splitting the data into two parts: one for training the model (called training data), and the other for the model to make predictions on (called test data). The predictions on the test data mimic how the model would perform with new, unseen data in a real-world scenario. We collect a lot of performance metrics from this process, which helps a human evaluate how well the model is doing.
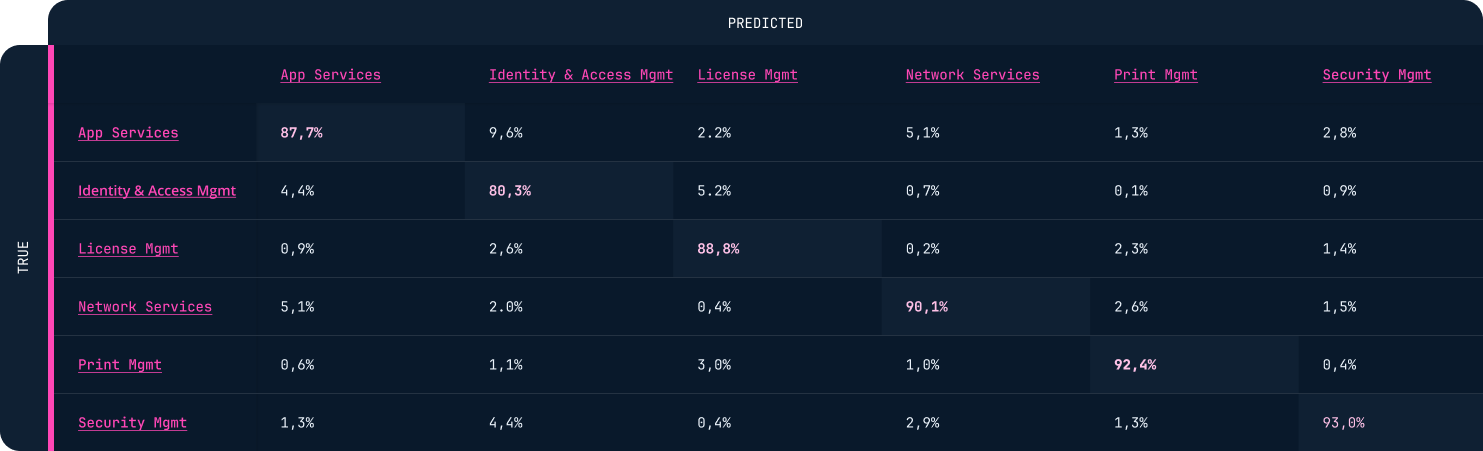
This is a confusion matrix where the test data for Auto Dispatch (or at least a sample of it) is evaluated. The confusion matrix should be read column-wise to show the precision of the predicted departments. Correct predictions appear in the diagonal and the distribution of the misclassified predictions can be seen in the other rows. High percentages in non-diagonal cells highlights where Auto Dispatch has difficulty distinguishing between two departments, indicating potential areas of improvement. The intersections between License Mgmt and Print Mgmt (3.0% and 2.3% respectively) may contain inquiries about printer licenses or other challenging inquiries to classify.
When comparing a new model to an old one, there can be several reasons for differences in performance. The most obvious ones include variations in the quantity or quality of data and changes to the algorithm during the development phase. However, the exact way a ML model works is a bit of a black box, and variations can also arise from randomness, like the random initialization of weights in a neural network.
This makes the evaluation phase a bit challenging, as it's not possible to precisely explain how the model operates. The key is to pay attention to the expected differences. For instance, in Auto Dispatch, if we have labeled inquiries about printer licenses, we'd specifically focus on metrics tied to the License and Print predictions, e.g. their intersections in the confusion matrix, along with examining sample inquiries related to printer licenses.
Operations Phases
Deploy

To make use of our theoretical and analytical efforts in building a ML model, we need to serve it so that it can be used by applications and analytics. Our approach is to serve the models via an API so that it can be integrated into different systems, such as our ticketing system.
Before deploying a new model to the production API, it goes through a validation process in both a development and a QA (quality assurance) environment. Just as developers are aware that deploying directly to the production environment is not good practice, the same reasoning applies to those of us working with ML.
Integrate
Now that we have a ML model API up and running and generating predictions - it’s time for some ML-magic!
Well, there is no magic involved, just ML Portal and logical rules.
Within ML Portal, Intility employees can link things like departments, instructions, documentation, templates, or whatever is relevant, to prediction categories, along with relevant meta data. When a system or application subscribes to predictions from the model API, ML Portal acts as the intermediary, providing all the requested properties to the system or application.
In the case of Auto Dispatch, our ticketing system subscribes to predictions from the model API. ML Portal supplies the department details and its operational time span for each prediction. This information enables the ticketing system, by logical rules, to determine whether an inquiry should be automatically dispatched or not.
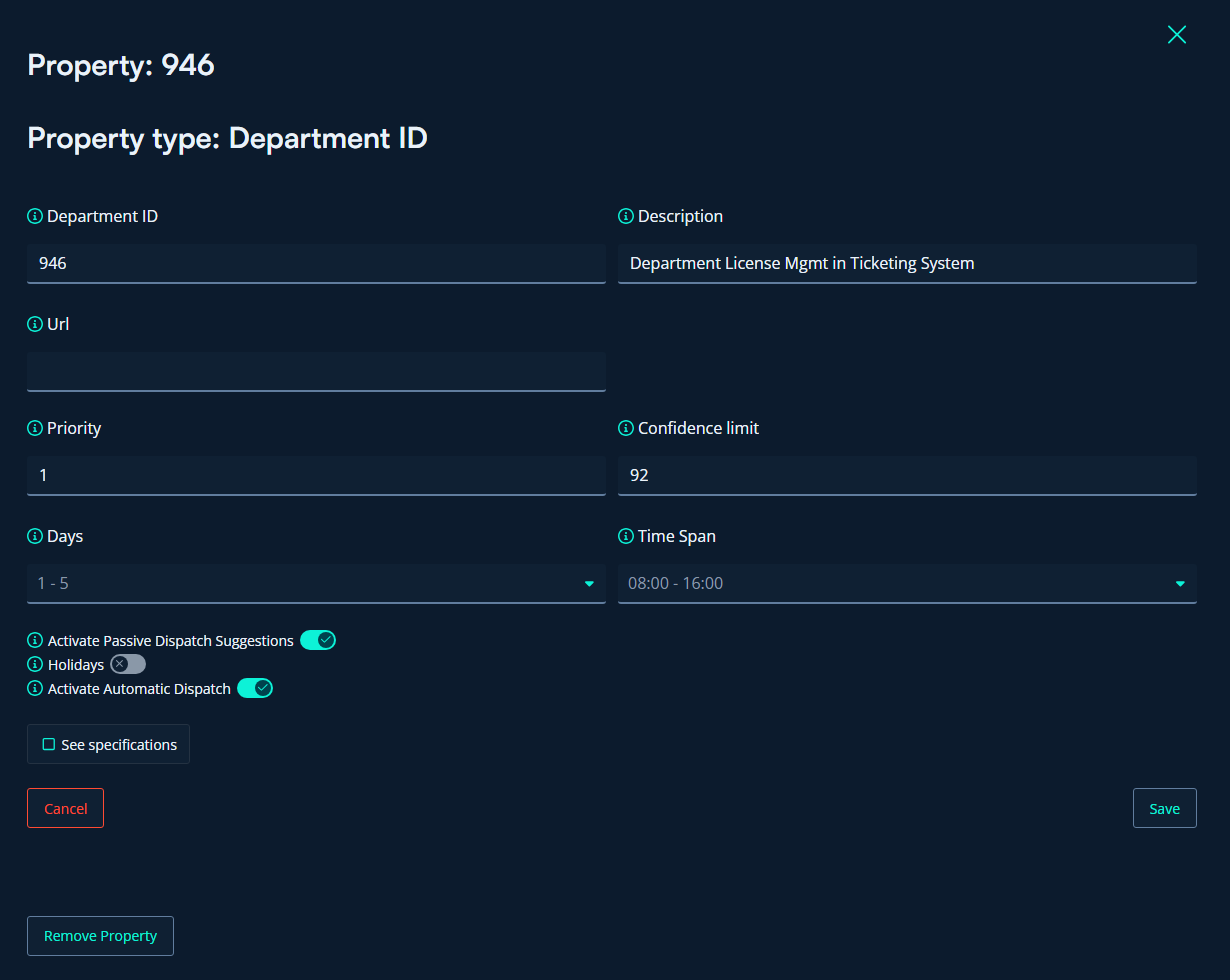
In ML Portal, we can manage properties like connecting the department in ML Portal to the department ID in the ticketing system, setting the confidence limit needed for automatic dispatches, defining the time frame for automatic dispatches, and more.
Inference

The Inference phase of the ML Ops cycle is where we utilize business value from the predictions generated from the operationalized ML model. Here, application design with a focus on user experience becomes crucial to ensure smooth usage of ML models.
At Intility, our Inference strategy doesn’t just focus on tasks that can be fully automated. Equally important is using ML to assist our employees by providing suggestions for actions. For instance, we have a lot of documentation that’s continuously updated, which can be a challenge for all employees to keep up with. By keeping the ML model up to date and using it to highlight suggestions for documentation, we're giving employees a shortcut that enhances their productivity.
We have a strong belief that ML will empower our employees both now and in the future. By enhancing the collaboration between humans and machines, we can unlock substantial benefits. That's why we put in a lot of effort to make sure our employees have trust in the ML models. We are aware that if the model gives poor suggestions, it could have a long-lasting negative impact on the user experience.
We take certain actions to address this concern. Firstly, we adopt a cautious approach when implementing new ML features and only release well-tested models. Additionally, we strive to maintain transparency by displaying the model's confidence percentage, acknowledging the possibility of incorrectly predictions from the model.
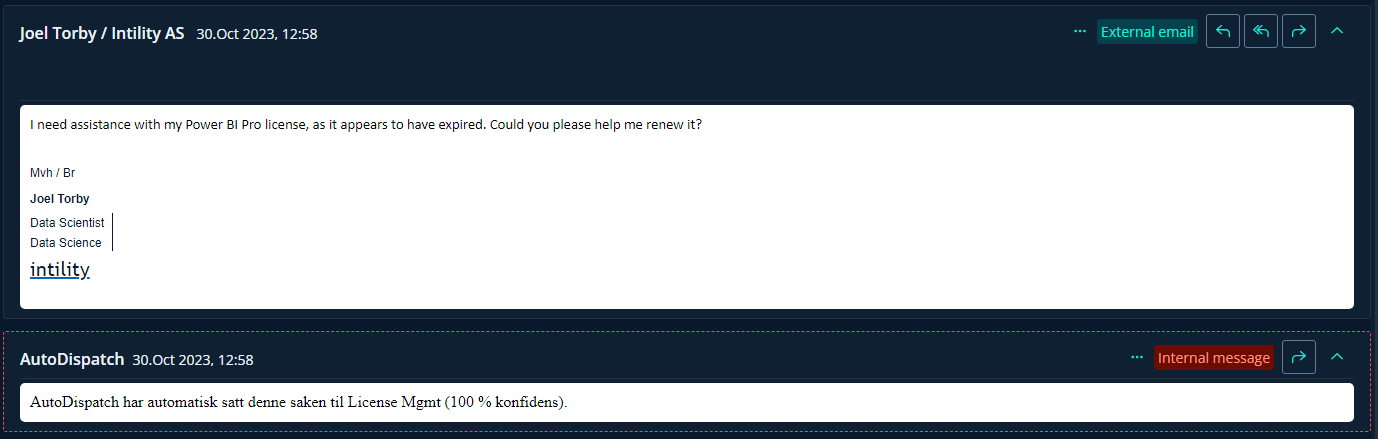
If Auto Dispatch is enough confident which department the inquiry belongs to, it gets immediately dispatched. This inquiry was well known for Auto Dispatch and the prediction confidence is above the given threshold for the License Department.
Monitor

In every end-of-the-world scenario, there's usually a machine that goes rogue, doing whatever it pleases and causing chaos. If we’ve done our job correctly during the evaluation phase, this shouldn’t be an issue. Still, it's comforting to be able to keep an eye on all the actions from the ML models in real time to ensure they're on track and doing what they're supposed to.
We use ML Portal to monitor the models. Using Auto Dispatch as an example, we're able to monitor in real time which inquiries are getting automatically dispatched, and to which departments. If something seems off, we're ready to step in and fix it before the model can cause any major problems.
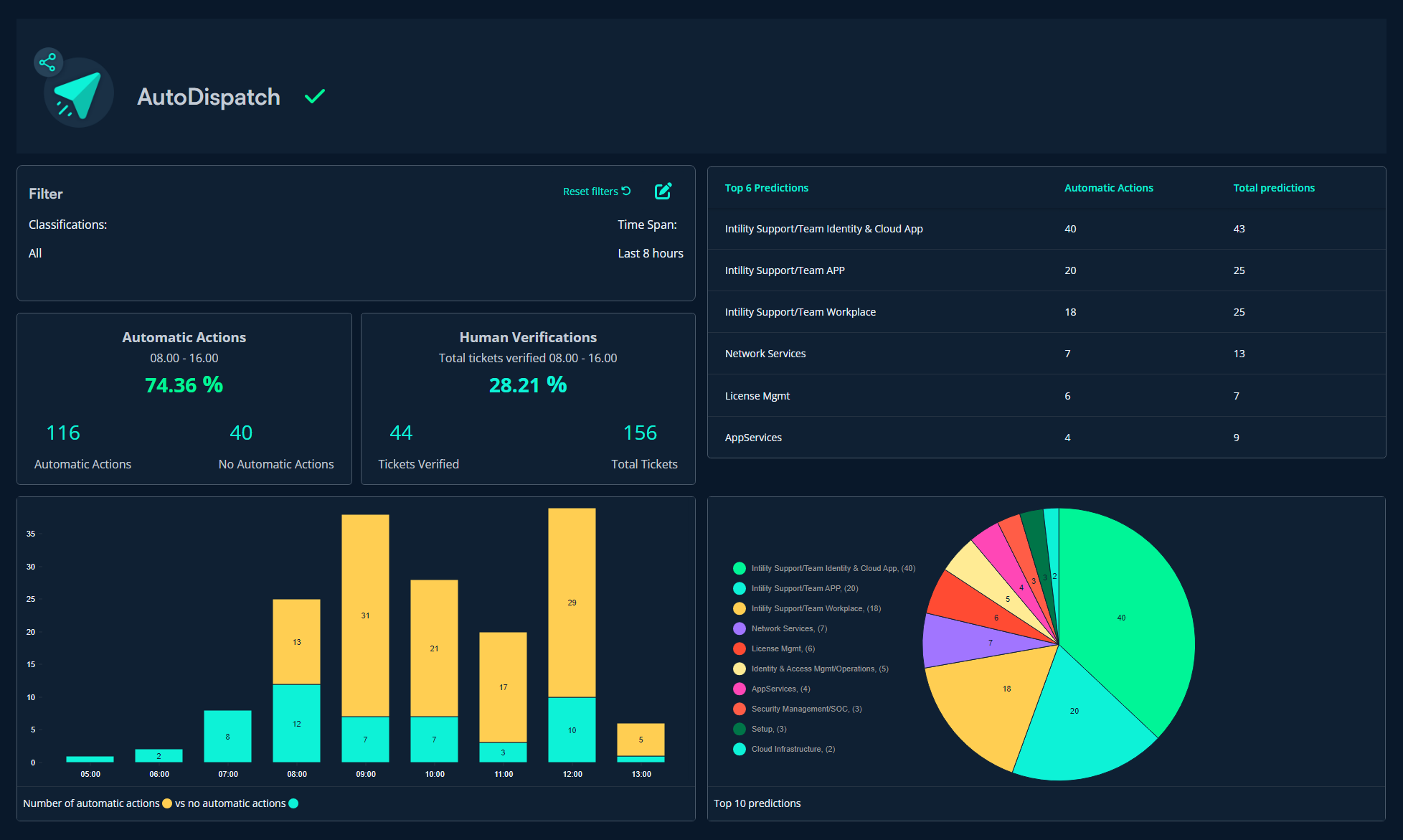
In the Auto Dispatch monitoring view, we can keep an eye on which inquiries are automatically dispatched to various departments throughout the day.
Data Verification
Each time a person interacts with the model, it creates valuable data that shows whether the model's prediction was useful or not. We also let employees to verify or un-verify ML predictions. These interactions and verifications contain valuable data which is stored in ML Portal. The data is then used to train the next model, ensuring that we learn from past mistakes and avoid repeating them. This not only improves the model in the next iteration of the ML Ops cycle but also builds trust in the collaboration between humans and machine, as employees are able to see model improvements based on their own verifications.
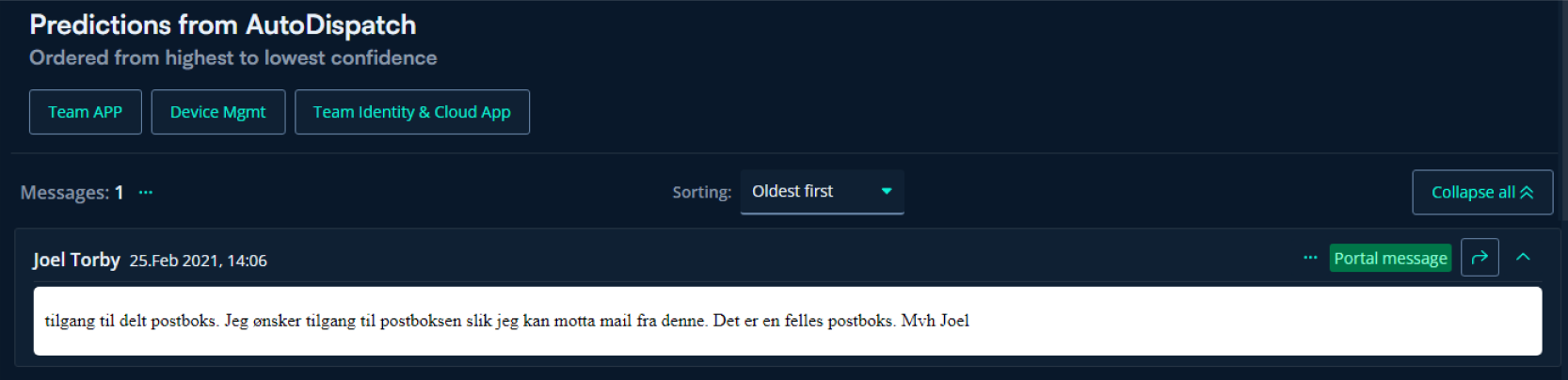
If Auto Dispatch isn't confident or it's outside working hours, it passes the decision to a human. The human can then choose a suggestion and verify it for future ML Ops cycles.
The ML Ops Cycle is finished, what now?
We've now taken a detailed tour through all the phases of the ML Ops cycle, but that doesn’t mean we’ve come to an end. The new data from the interactions and verifications goes into the Data Analysis phase where it might be discovered to improve the model’s confidence on its ongoing tasks or to spot new issues for the model to tackle. So, the cycle keeps on rolling.
Summary
After this detailed tour of all the steps in the ML Ops cycle which allows for infinite iterations of improvement, it feels like an understatement to claim that ML Ops is more than just a one-time task of training and deploying a model.
But realizing the potential of ML goes way beyond having a consistently high performing model over time. It's the collaboration between humans and machines, rooted in trust, that deserves our primary attention.
At Intility, our belief is that trust grows when the machine is capable of quickly adapting to human feedback. With ML Portal as the crucial component in the ML Ops cycle, we are able to narrow the gap between humans and machines and thereby realizing the potential of ML at Intility.
if (wantUpdates == true) {followIntilityOnLinkedIn();}
Other Articles




Platform
June 26, 2026
Beyond Intelligence: Benchmarking Speed and Cost of Self-Hosted vs. Frontier LLMs

Erfan Mohammadi

