
How to Build an Inference Platform
Written by
June 5, 2026
|
Approximately a 00 minutes read
Platform
Pick a model, hit deploy, and within seconds you can build on a 744-billion-parameter language model through your own private endpoint. No support tickets, no external API dependencies and no data ever leaving Intility infrastructure. In this post I explain how we put it together.
But before we get into how, I want to tell you why.
The use of large language models is growing fast, and no longer only at the edges of our business. We use them to write code, talk to our platform through MCP servers, run autonomous agents, and to navigate our docs. As inference moves from pilot projects into our core systems, taking deep control over the infrastructure powering those systems is a natural next step.
We're a company that believes in owning its supply chain, and inference is now part of that supply chain. Building our own platform puts five things back into our control:
- Data. Where do our prompts go, and what are they used for? When we own the stack, the answer is simple: nowhere we don't control. This allows for tighter integration and more powerful results as we can send full context without hesitation.
- Cost. At our scale, the per-token pricing adds up fast. Hardware prices are fixed, and the more we use it, the better the math looks.
- Compliance. Regulatory requirements are far easier to meet when the data never leaves infrastructure we operate.
- Availability. When someone else's API goes down, we wait. When it's ours, we fix it.
- Predictability. No sudden pricing changes, no surprise model deprecation and no shifting terms of service underneath the systems we've built on top.
Let's get to building!
The infrastructure
We started with what's arguably the most solid foundation available: the most powerful GPUs on the market at the time, NVIDIA HGX H200 systems. For the infra-geeks, each of these is an 8×H200 box packing a solid 1,128 GB of GPU memory. For comparison, the leading consumer card, NVIDIA's RTX 5090, ships with 32 GB. This is the kind of hardware you need to serve frontier open-weight models.
Two things were clear from the start. The platform had to be a first-class part of our existing platform, and it had to run on Kubernetes. Kubernetes was a no-brainer for us. It's powerful, extensible, and has an open-source ecosystem we already know and trust.
The more interesting decision was the operating system. We've recently been impressed by Talos Linux, a minimal, immutable, API-driven distribution built for one job: running Kubernetes. There is no shell, no SSH, and no runtime install of packages. The entire cluster is configured declaratively and managed over an API. For those who care about GitOps, this should make you happy. Combine it with excellent NVIDIA driver support and you have a great base for running a GPU cluster.
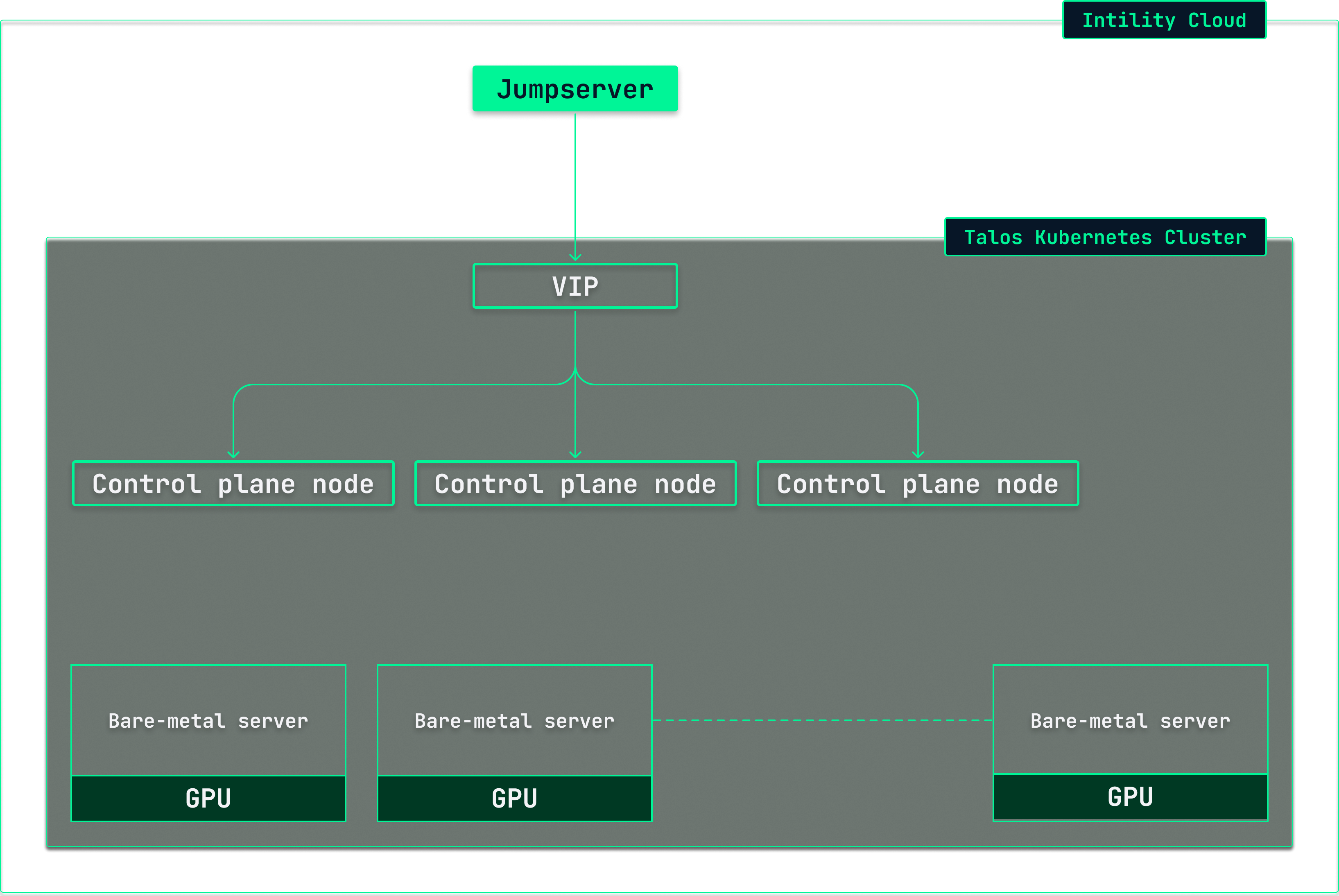
The software stack
With the hardware and operating system in place, we had a Kubernetes cluster full of GPUs. Turning this into a production-grade inference service came down to four decisions: how to run a model, where to store it, how to route requests to it, and how to expose it to users.
The inference engine
An inference engine is the piece of software that takes a set of model weights, the billions or even trillions of numbers that govern the statistical behaviour of an LLM, and serves them through an API. If you have experimented with running language models locally, you might have used Ollama. Ollama is great for lightweight deployments, but if you want to run enterprise level hardware and maximize throughput there are only two choices in my opinion: SGLang and vLLM.
We went with vLLM. It has the fastest and broadest model support, and as far as I can see, the most active community. That matters when you want to offer the latest and greatest open-weight models, or run a more obscure model to cover a niche business need.
In reality, the inference engine handles a lot more than "just running the weights". For brevity I will avoid diving deeper into too much of the awesome engineering work in such a piece of software, but I would like to explain two core concepts of LLMs. Firstly because this will help you understand some of the problems that arise when serving LLMs, and secondly because I think this is interesting information that might explain some LLM behaviour you probably have experienced before.
The processing of an LLM request can be split into two phases: First the model needs to process your input (this is called prefill) before it can start generating the answer (this is called decode). Prefill is fast: all the input tokens can be processed in parallel. Decode is slow: the answer is generated one token at a time, each new token depending on the one before it.
The engine is responsible for scheduling all of this. Because prefill and decode compete for the same GPU, it constantly has to decide which to prioritise. That choice is a lever: favour prefill and new requests start answering sooner (lower time-to-first-token), favour decode and you push more total tokens through the box (higher throughput). Tuning that balance is an important knob you have as an inference operator. Here is a stripped down deployment showcasing how we control this balance in our vLLM deployments.
apiversion: apps/v1
kind: deployment
metadata:
name: glm-5-1
spec:
replicas: 2
template:
spec:
# we want to run this model on our hgx nodes.
nodeselector:
nvidia.com/gpu.family: hopper
containers:
- name: vllm
image: vllm/vllm-openai:v0.21.0
args:
# pull glm 5.1 weights from huggingface
- "zai-org/glm-5.1-fp8"
# we allow vllm to process both decode and prefill together
- "--enable-chunked-prefill"
# max tokens processed per pass. This keeps large prompts from freezing decode
- "--max-num-batched-tokens=8192"
Without chunked prefill, a user sending a 100,000-token prompt would freeze the GPU for everyone else while it works through that input. Chunked prefill turns the input into a series of smaller passes, and the token cap is the size of each slice. Decode keeps moving between every slice, so active responses stay generating even when large new requests are being admitted.
But before the engine can run a model, it first has to load one, and at this size that is something you have to plan for.
The storage solution
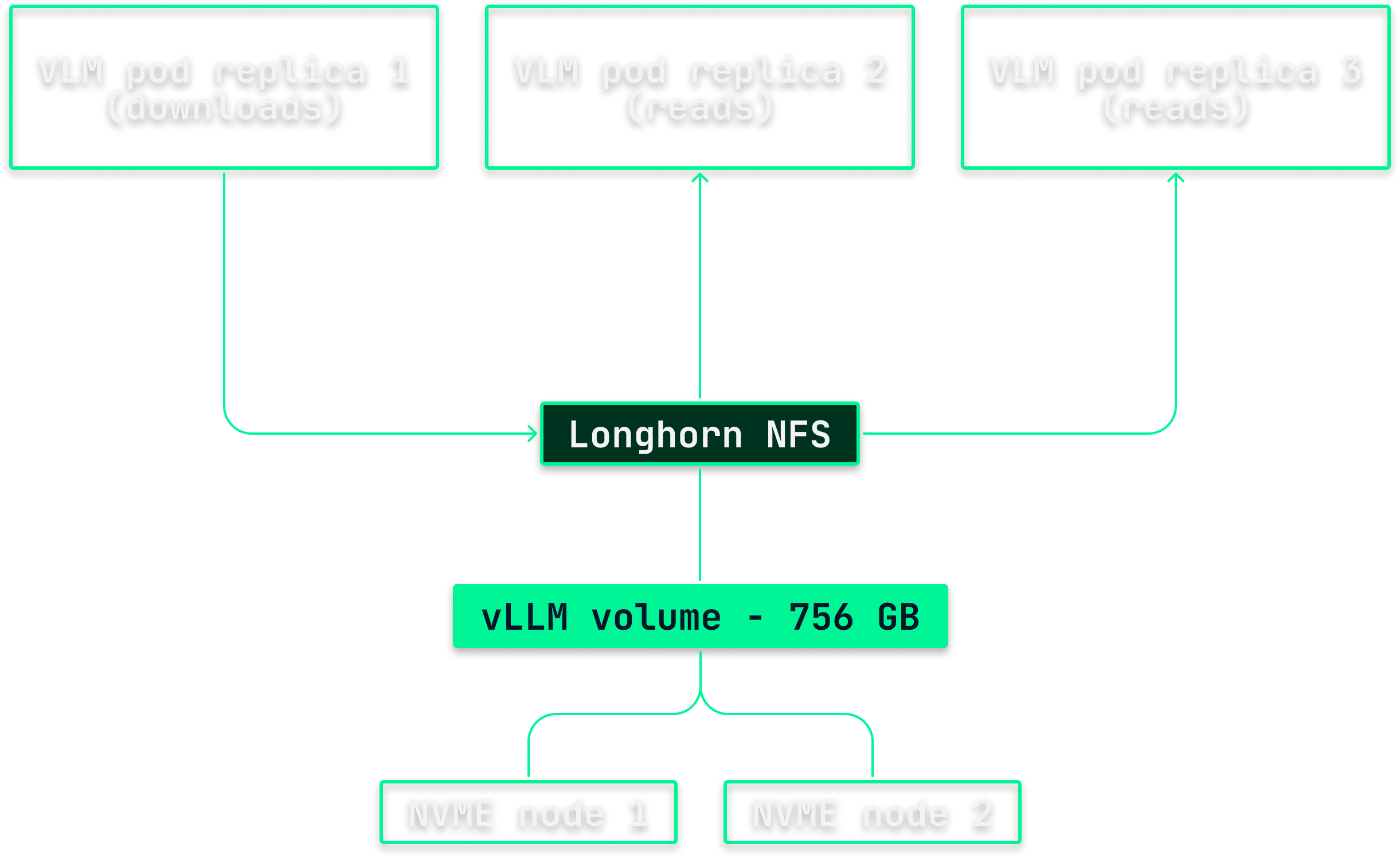
Large language models are large. GLM 5.1, for example, has 744 billion parameters, which at 8-bit floating point precision (FP8) is 756 GB of weights. If you've run Kubernetes workloads before, you'll know we need some form of network-attached storage. Pods running LLMs have to move between nodes with as little downtime as possible, and we can't simply pin a copy of every model to every node. With models this size, that would send our storage needs through the roof.
This is a balancing act between two competing goals. We want to avoid replicating the weights everywhere, but we also need enough copies, on enough nodes, that a pod can be scheduled quickly and survive a node going down. Distributed block storage solves both. Plenty of good open-source options exist here, but we went with Longhorn for its simplicity.
The reason this matters so much becomes obvious the first time you start a model from scratch. Pulling 756 GB from Hugging Face, loading it onto the GPUs, and capturing CUDA graphs can take the better part of an hour. You do not want to pay that price on every pod restart, and you definitely do not want to pay it once per node.
So each model gets a single ReadWriteMany volume that holds its weights. The first vLLM pod downloads the model into that volume, and every other replica of the same model mounts it and reads the same copy. Underneath, Longhorn keeps a couple of replicas of the volume across nodes for redundancy, and serves them to every pod through a shared network mount. That network hop is marginally slower than reading from local disk, but it is a one-time cost at startup, and a small price for the storage we save by not pinning a full copy of every model to every node.
The routing layer
This is in my opinion the most interesting part of building and running an inference platform. Traffic in the world of inference is a lot different from regular web traffic, which results in a bunch of issues with the classic routing approach.
The biggest problem was seen during experimentation, where the much-loved round-robin strategy in some cases led to staggering results like 50% slower and more expensive requests than strategies optimized for inference. To understand why, we need to do a small detour through caching.
- As we talked about earlier, the inference process can be split into prefill and decode. If the inference engine has already processed a given input sequence once, it can cache the result of that prefill and skip recomputing it the next time the same sequence shows up.
- A quick example of why that matters so much: LLMs are stateless. They don't remember anything between requests, so every new message in a chat has to resend the entire conversation so far. In a long back-and-forth, a one-sentence follow-up question can drag hundreds of thousands of tokens of history along with it, all of which would normally need to be prefilled again. That is expensive. To remedy this, engines like vLLM can keep the prefill result in GPU memory, and on your next message, the earlier input can be pulled from cache instead of being recomputed.
So caching is cool, but leaves us with a routing problem: How do we make sure that the large multi-step requests from chats and coding agents always hit the same GPU? The easiest solution would be to only run a single replica deployment. The real answer is cache-aware load balancing. It works by having the router hash parts of each request, usually the system prompt + the conversation history up to some point, and keeping track of which targets are sent which hashes. When a new request with a matching hash comes in, it can be redirected to the GPU most likely to contain the cached computation. Notice I used the term "most likely". The process is probabilistic, as vLLM exposes no API the router can ask "does this pod have cache X". Caches come and go as new requests evict old ones and pods restart.
(I attended KubeCon '26 in Amsterdam, and this was the topic of at least 5 of the talks I sat in on. Luckily, when the community is that interested in a problem, good solutions are likely to exist.)
The choice of inference router depends on your scale and ecosystem integration, but for us the Kubernetes-native EndPointPicker from the Gateway API Inference Extension SIG came out on top. In addition to basic prefix routing it scrapes vLLM's metrics to understand the queue depth and cache utilization. In practice it looks something like this
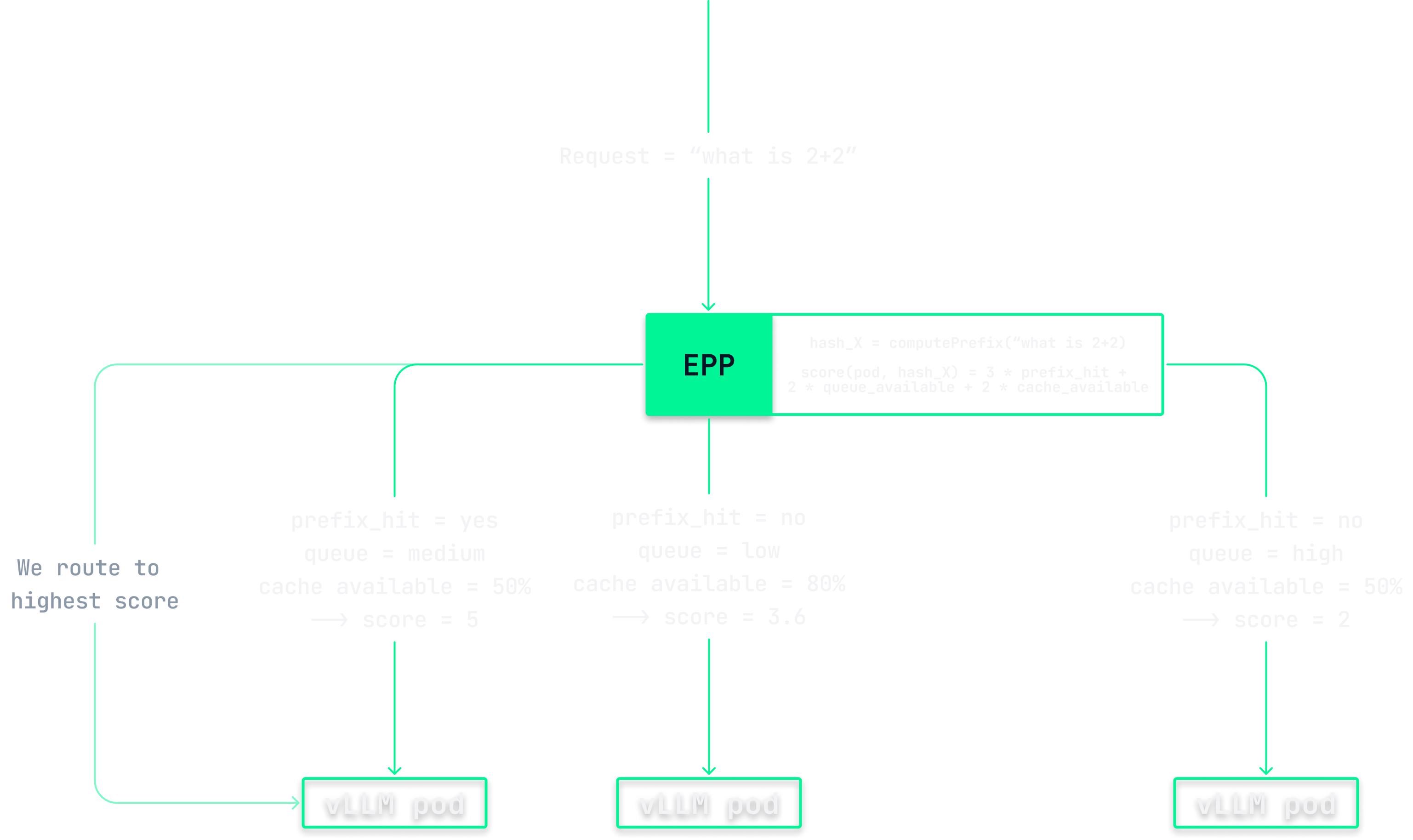
This scoring function from the illustration is the one we run with btw. If you want to know more about it check out the official docs. At much larger scale, alternatives like NVIDIA Dynamo or llm-d offer more advanced techniques for optimizing throughput such as disaggregated prefill and decode, running prefill and decode on separate GPUs. This is powerful, but on our current scale the simplicity of the EndPointPicker won us over.
Our current state: we have multiple LLMs running on our cluster ready to accept requests with optimal probabilistic routing. One thing is obviously missing though: how does a request get into the cluster in the first place?
The gateway
After years of offering managed Kubernetes to internal and external teams, we have developed a love for the Envoy Gateway project. However, as with routing, no classic gateway is built to handle the demands of inference traffic.
Ordinary web traffic tends to be short-lived, deterministic and billed uniformly per request. Inference requests on the other hand follow different patterns.
- Responses are probabilistic: The same request can produce different outputs, and different amounts of output each time.
- Requests are long-lived. A streaming response with a large context can run for minutes, not milliseconds.
- Usage has to be measured, not counted. Billing and quotas depend on input and output token counts, not on the number of requests.
- Rate limiting changes shape. Because a single request can be trivial or enormous, and because limits have to apply per authenticated user, rate limiting has to happen after authentication and key off identity rather than IP.
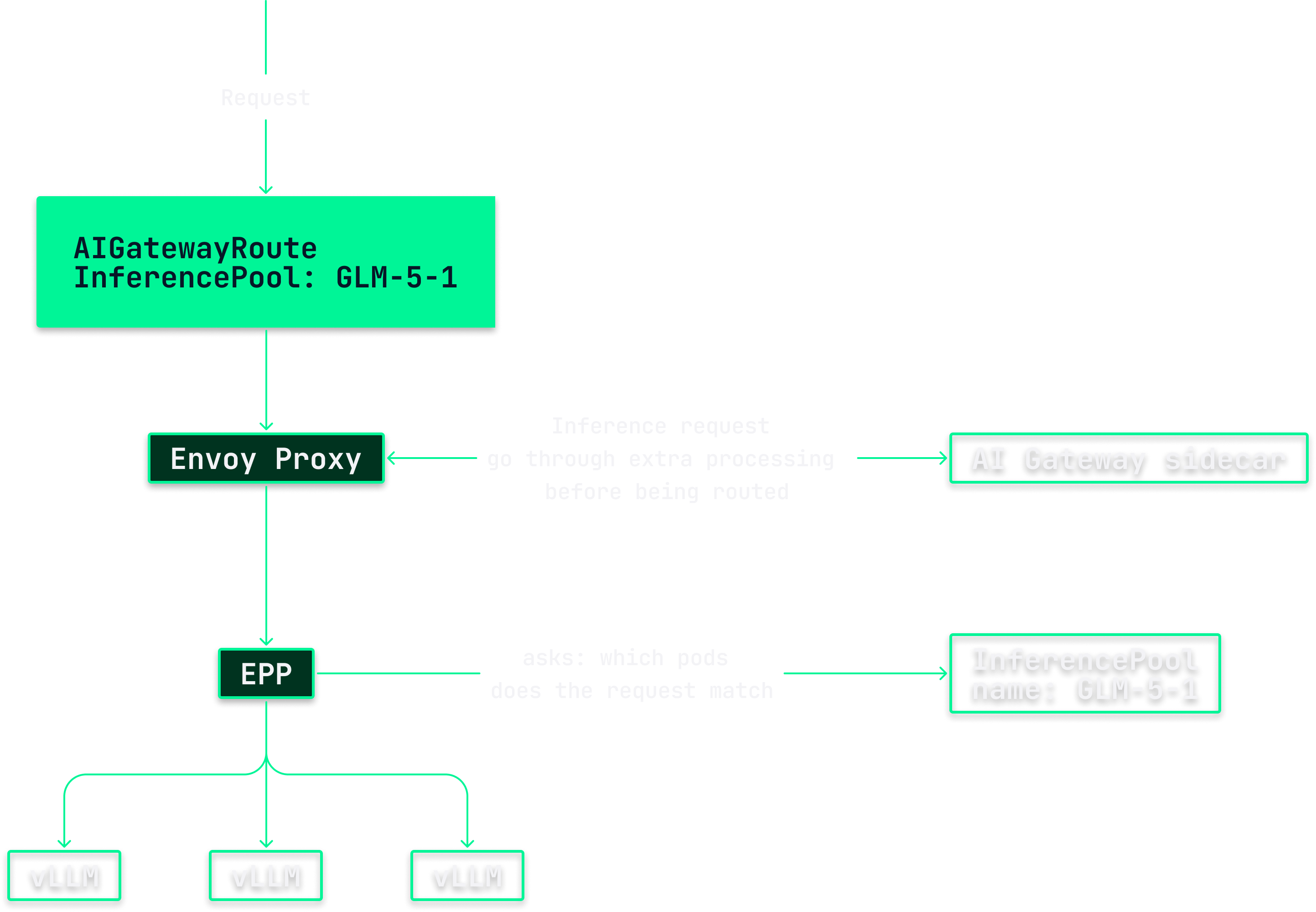
Luckily, the Envoy Gateway team had already started building an AI Gateway extension aimed at solving all of these problems. In addition to being great tech, the community is responsive and has proven that our decision to build on top of Envoy was a good one. Envoy AI Gateway works by injecting a sidecar into the Envoy Gateway that makes sure inference requests are routed through additional processes before being passed on. On the way in it adjusts paths, adds the headers downstream components rely on, and enforces our per-user request limits. On the way out it extracts token usage from the response and ships it to our usage service to be persisted for billing.
To make all of this available, the AI Gateway project introduces its own resource for exposing a model, the AIGatewayRoute, which becomes the central unit we hand out to our users.
It's time to get access
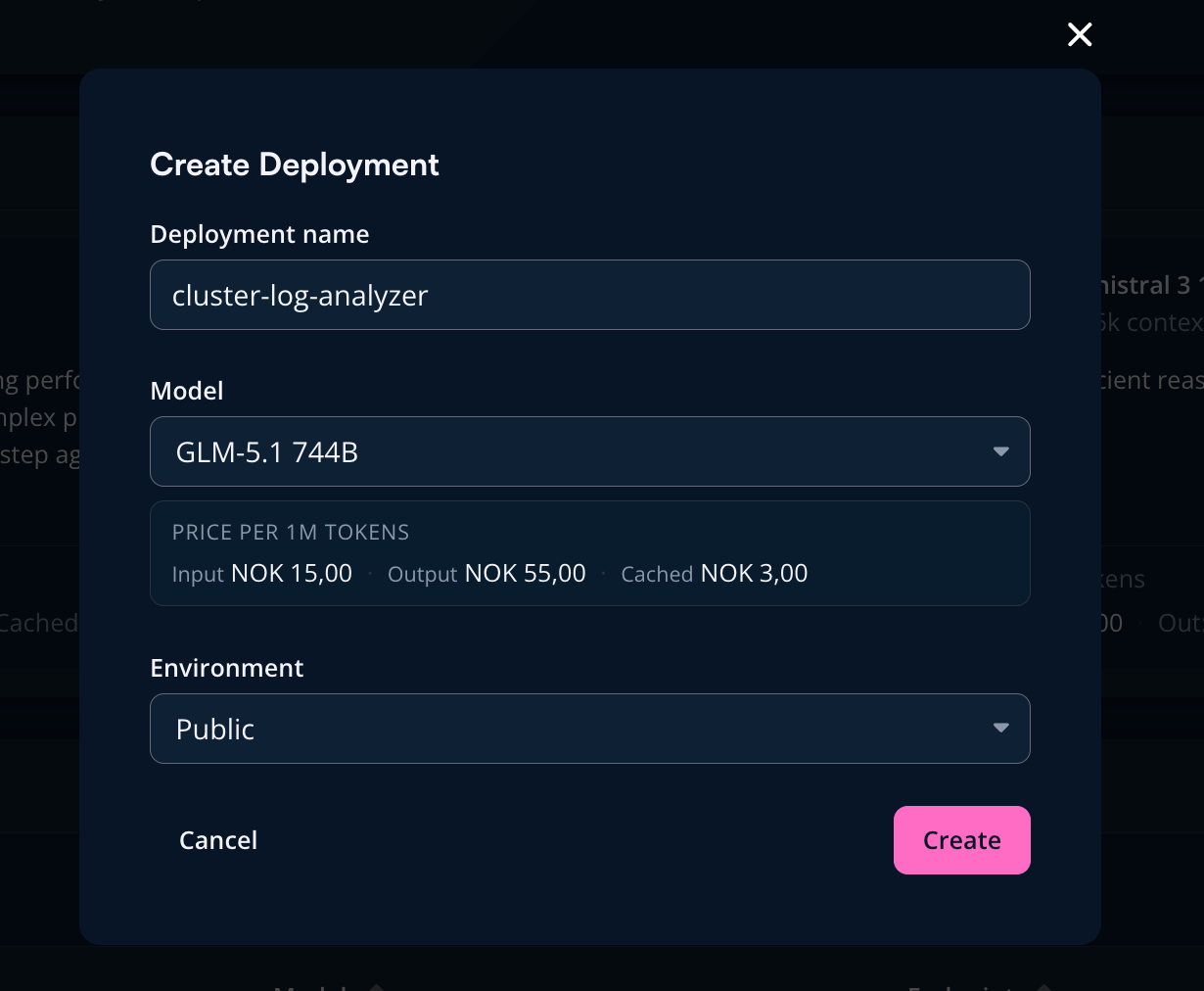
What we now have is pretty cool, but not very useful until our coding tools, autonomous agents and customers actually can consume it. My department is tasked with making the developer experience as good as possible, which made it a natural choice to integrate the inference offering with our developer platform. (Take a look at Stian's blog post to read more about it!). From the developer platform, a user can now order a deployment in seconds, getting a personal API endpoint for their model of choice. The wiring of AIGatewayRoutes happens behind the scenes and the user is met with an easy abstraction.
What's next
The field of AI moves fast. New frontier models top the leaderboard in one category or another seemingly every week, and hardware just keeps getting better. Every generation of GPUs unlocks larger and faster models, and new machine learning techniques push the hardware further. Our next step rides that wave, as we move onto NVIDIA's Blackwell generation and its native FP4 support, which roughly halves the memory a model needs to store most of its weights. This lets us serve larger models and more concurrent users.
Staying at the frontier isn't a one-time investment. It means continuing to invest in new GPUs as they arrive, and continuing to contribute back to the open-source projects we build on, vLLM and Envoy AI Gateway among them, that made this platform possible in the first place.
On the technical side, the harder problems we've deliberately left on the table start to get interesting. Disaggregated prefill and decode is a challenge that only shows up at real scale, and one I hope we get to take on in the near future. When we own the whole stack, how far we go is up to us.
if (wantUpdates == true) {followIntilityOnLinkedIn();}
Other Articles




Platform
June 26, 2026
Beyond Intelligence: Benchmarking Speed and Cost of Self-Hosted vs. Frontier LLMs

Erfan Mohammadi

Automation
March 5, 2026
Running AI Agents in Automated Workflows: What If Your Documentation Wrote Itself?

Benjamin Omar Joof